Technical writing using Markdown
This blog was inspired by this PeerJ article and relies heavily on the same for content.
Note: This blog was written in Markdown.
Why Markdown?
There are currently 2 options for academics seeking to write technical reports/papers: MIcrosoft Word or LaTeX. From a writer's perspective, the use of What You See Is What You Get (WYSIWYG) such as Microsoft Word, WPS Office, or LIbreOffice might be convenient, because the formatting of the document is directy visible. But the complicated syntax specifications often result in problems when using different software versions and for collaborative writing. Simple conversions between file formats can be difficult or impossible. Academic writers might also face the problem of abruptive changes in the document structure; even with an insertion of a single letter. This becomes problematic while working on a large report leading to exasperation and frustation. Not only that, these are very slow and can consume large virtual memory, upto a gig sometimes.
It becomes problematic when you have to convert your files to different file formats for various reason. For example:
- For submitting a journal manuscript for peer-review in DOCX, as well as a preprint version with another style in PDF.
- For submitting your manuscript to journals with considerably different citation styles.
- For publishing a book with print version in PDF and an electronic versio in EPUB.
On the other hand, some people work with LaTeX; particularly in the scientific community. With LaTeX, documents with high typographic quality can be produced. However, the source files are cluttered with LaTeX commands and the source text can be complicated to read. Therefore, LaTeX is not user friendly, especially for casual writers or beginners.
Markdown is a plain text markup language which is both lightweight and easy to read and write. It can be easily converted into common formats, such as PDF, HTML, DOCX or EPUB using Pandoc. John Gruber, the original developer of Markdown, defined the goal for Markdown as follows:
The overriding design goal for Markdown’s formatting syntax is to make it as readable as possible. The idea is that a Markdown-formatted document should be publishable as-is, as plain text, without looking like it’s been marked up with tags or formatting instructions.
The figure below compares formatting elements and their implementations in different markup languages (image source).

In this blog, I'll explain how to write manuscripts in plain markdown text files recognised by .md file extension which can be easily converted into common formats, such as PDF, HTML, DOCX or EPUB using Pandoc. Apart from that, the use of templates enable the automated generation of documents according to specific journal styles. The simple syntax of markdown facilitates document editing and collaborative writing. Reducing the work spent on manuscript formatting translates directly to time and cost savings for all stakeholders, such as writers, publishers and readers.
A brief introduction to markdown syntax
Special symbols are used for formatting texts.
# A h1 header
## A h2 header
### A h3 header
*Italic*, **bold** and ***both***
Paragraphs are separated by a blank line.
Here is an unordered list:
- apple
- green apple
- red apple
- banana
- orange
and it would be rendered as
- apple
- green apple
- red apple
- banana
- orange
Here is a numbered list:
1. apple
1. green apple
1. red apple
2. banana
5. orange
and it would be rendered as
- apple
- green apple
- red apple
- banana
- orange
Here is a link to the my website
[Pankaj Kumar](https://pankajkarman.github.io/)
and it would be rendered as
~~Strikethrough text~~
would be rendered as
Strikethrough text
Some text ~Subscript~
Some text ^Superscript^
A list of useful links for further learning about Markdown
Markdown Editors
While any plain text editor can work with markdown, there are some editors dedicated for markdown providing key bindings for common operations like making text bold, italic etc. Some of the open-source editors are:
Writing reports/papers
Link for markdown paper-template.
Markdown relies on pandoc for all conversion tasks. Please follow the steps mentioned in the above link for installation of all dependencies. Installation steps may differ depending on the operating system. Instruction mentioned in the link are pretty generic and can be easily followed on any operating system.
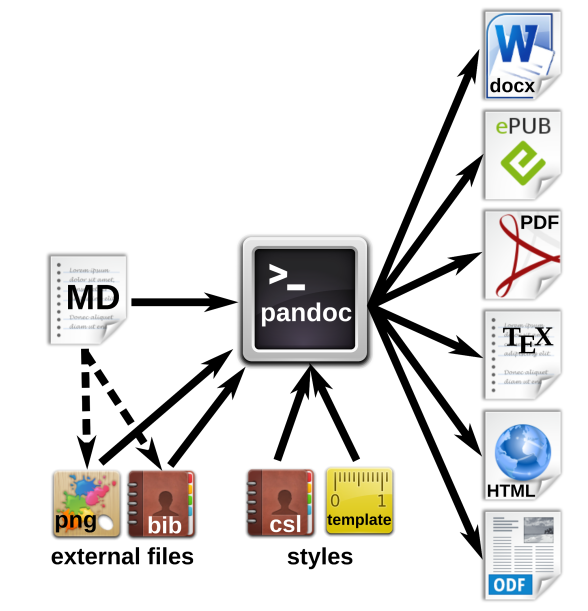
The above figure shows the workfow for the generation of multiple document formats with Pandoc (image source). The markdown (MD) file contains the manuscript text with formatting tags, and include references to external files such as images or reference databases. The Pandoc processor converts the MD file to the desired output formats. Documents, citations etc. can be defined in style files or templates.
Now, I'll describe the procedure for typesetting scientific manuscripts with Pandoc, a swiss army knife for document conversion, using examples for typical document elements, such as tables, figures, formulas, code blocks and references. For more detailed discussion, please refer to the pandoc manual.
Tables
There are several options to write tables in markdown; with pipe tables being the most flexible. The contents of different cells are separated by pipe symbols.
| Syntax | Description | Text |
| :---- | :----: | ----: |
| Header | Title | Here's this |
| Paragraph | Text | And more |
would be rendered as
Syntax Description Text Header Title Here's this Paragraph Text And more
On one hand, syntax for writing tables is very simple but it may very time consuming while generating bigger tables. To simplify the process of table generation, I have written a python script to generate a markdown table using python. The linked github repository contains an example notebook demonstrating the table generation and the same has also been shown below.
import pandas as pd
import pandoc
df = pd.read_csv('tables/surf.stn.md', sep='\s+')
tab = pandoc.Table(df)
tab.to_markdown('table.md')
The above python script saves the generated markdown table in a file named table.md which contains:
|Stations|Latitude|Longitude|Altitude| Period |
|--------|-------:|--------:|-------:|---------|
|marb | -64.24| -56.62| 198|2011-2015|
|mcmu | -77.82| 166.58| 11|1986-1992|
|arht | -77.80| 166.67| 184|1996-2015|
|neum | -70.65| -8.25| 42|1982-2014|
|spol | -89.98| -24.80| 2810|1975-2015|
|syow | -69.00| 39.58| 16|1997-2015|
Images
An image can be inserted in markdown using:
{#figure1 width=55%}
Here, figure1 is an identifier for the figure defined with # along with image dimension in braces.
The above text would be rendered as

Equations
Equations are written in LaTeX mode using the delimiters $.
You can specify an inline quation like LaTeX $x^2+y^2=z^2$
Or a block level equation with two dollar signs on both sides of the equation:
$$\sum_{i=0}^n i^2 = \frac{(n^2+n)(2n+1)}{6}$$
Code blocks
To write code, you indent it by 4 spaces or a tab. Markdown will guess what language you are writing
def main():
print "Say Hello!!"
would be rendered as
def main():
print "Say Hello!!"
You can specifiy which programming language you are using with delimited blocks if you wish
```python
def say_hello():
print('Hi Everybody')
```and it would be rendered as
def say_hello():
print('Hi Everybody')
Citations/References
The efficient organization and typesetting of citations and bibliographies is crucial for academic writing. Pandoc supports various strategies for managing references. For processing the citations and the creation of the bibliography, the command line parameter --filter pandoc-citeproc is used, with variables for the reference database and the bibliography style. A separate .bib file must contain the database of all references with corresponding keys. The used database can be defined either in the YAML metablock of the markdown file or it can be passed as parameter when calling pandoc. Softwares like Mendeley and Zotero can help in creating and maintaining reference databases.
A citation is inserted by using the citation key given within square brackets preceded by '@' as follows:
[@Solomon2016; @kuttippurath2018]
The generated references will be inserted automatically below the header # References or # Bibliography.
Citation style
The Citation Style Language (CSL) is used for the citations and bibliographies. This file format is supported by all reference management softwares like Mendeley, Zotero etc. CSL files for a number of journals can be found at this link. The bibliography style that pandoc should use for the target document can be specified in the YAML block of the Markdown document or can be passed in as a command line option. Journal reference styles can be easily changed by just changing CSL file to be used; saving lots of sweat while doing the adjustment as in MS Word.
Meta information
Document information such as title, authors, their affiliation, correspondence details, abstract, keywords etc. can be defined in a metadata block written in YAML syntax. Variables defined in the YAML section are processed by pandoc and integrated into the generated documents. The YAML metadata block is recognized by three hyphens (---) at the beginning, and three hyphens at the end. for example:
---
title: Climate change causes increased heat waves
subtitle: heat waves
date: 2020-05-22
---
Pandoc filters
Pandoc supports lua and python based filters to aid in formatting of the documents. For example: pandoc-citeproc parses the citations included in markdown files, pandoc-crossref allows numbering and cross-referencing of figures, tables and equations across the document. Filters should be specified on the commandline with --filter filterpath or -F filterpath parameter. For example:
pandoc -F pandoc-citeproc -F pandoc-crossref -o example.docx example.md
I have written one python filter for inserting any external text in markdown. This filter inserts the text inside the file specified using !include filename.md. This filter should be run separately as a python script as follows:
python python-include.py --infile infile.md --outfile outfile.md
Have a look at this link for more information regarding pandoc filters and this link for a list of available third party filters.
Automatising document generation
While generation of documents can be automatised using shell scripts, but I prefer to use Makefile for the same. Makefiles are similar to shell scripts with an important difference. While shell script executes the commands specified in it irrespective of the status of files, Makefile considers the status of target files specified when executing a command.
For example: Makefile provided in paper template repository consists following:
fig = ./figures/
tab = ./tables/
bib = ./ref.bib
csl = ./template/nature.csl
filters = ./filters
template = ./template/paper.tex
ref = /home/Mendeley/ref.bib
upp = ./head
main = ./main
tem = ./doc.md
lua = --lua-filter=$(filters)/pagebreak.lua \
--lua-filter=$(filters)/scholarly-metadata.lua \
--lua-filter=$(filters)/author-info-blocks.lua
arg = -F pandoc-crossref -F pandoc-citeproc
com1 = cat $(upp).md $(main).md > $(tem)
com2 = python $(filters)/pandoc-include.py --infile $(tem) --outfile $(tem)
com3 = pandoc $(tem) $(arg) --csl $(csl) --bibliography $(bib)
com = $(com1); $(com2); $(com3)
all: pdf docx
bib: $(ref)
cp $(ref) $(bib)
copy:
cp /home/pankaj/figures/*.pdf $(fig)
cp /home/pankaj/tables/* $(tab)
pdf: $(main).md $(upp).md $(bib)
$(com) -s --template=$(template) --pdf-engine=xelatex -o $(main).pdf
rm -rf $(tem)
docx: $(main).md $(upp).md $(bib)
$(com) $(lua) -o $(main).docx
rm -rf $(tem)
clean:
rm -rf *.pdf *.docx
Above Makefile can be modified appropriately to specify proper paths for images, tables, csl file, bibliography file (.bib), pandoc filters and templates to be used for document generation. Variable upp points to the header markdown file with appropriate YAML blocks to be included in generated documents. Variable main points to markdown file being edited (main.md in this case).
arg = -F pandoc-crossref -F pandoc-citeproc
com1 = cat $(upp).md $(main).md > $(tem)
com2 = python $(filters)/pandoc-include.py --infile $(tem) --outfile $(tem)
com3 = pandoc $(tem) $(arg) --csl $(csl) --bibliography $(bib)
com = $(com1); $(com2); $(com3)
Above lines specify the appropriate arguments to be used for pandoc commandline. Instruction to execute Makefile has been provided in the accompanying paper-template repository. For example: pdf output can be generated using make pdf command. Similarly docx can be generated using make docx command. Running command make all or make will generate both pdf and docx outputs. For generating pdf output, LaTeX should be installed on the system before executing the Makefile. Generated docx file might require a little bit of tweaking before shared/submitted.
Version control
Git is one of the most employed software solutions for versioning. Git allows the parallel work of collaborators, and has an efficient merging and conflict resolution system. A Git repository may be used by a single local author to keep track of changes, or by a team with a remote repository; for example, on Github or Bitbucket. Because of the plain text format of markdown, Git can be used for version control and distributed writing. Follow this link for learning how to use git.
Comments
Comments powered by Disqus